Comment configurer un fichier Robots.txt sur Webflow pour optimiser son SEO ?

.avif)
.avif)
.avif)
.avif)
Webflow est un outil polyvalent pour obtenir un bon référencement naturel (SEO). Le logiciel est équipé nativement d’un outil d’aide au SEO. Savoir bien configurer ses différents paramètres vous donnera toutes les chances de bien positionner votre site sur les requêtes Google pertinentes.
Les fichiers robots.txt font partie des paramètres que vous pouvez régler et qui contribuent à générer du trafic sur votre site. En effet, ils assurent le bon fonctionnement des robots d’analyse de contenu des moteurs de recherche. S’il est bien configuré cela va vous permettre d’améliorer votre note SEO.
Vous trouverez dans cet article tout ce qu’il faut savoir pour configurer
correctement votre fichier Robots.txt sur Webflow.
I. Qu’est-ce qu’un fichier robots.txt ?
Un fichier robots.txt est un fichier texte attaché à votre site web. Il s’occupe d’autoriser ou non le passage des robots qui indexent vos pages dans les différents moteurs de recherche.
Vous pouvez ainsi cacher certaines de vos pages aux yeux de Google,
mais elles resteront toujours disponibles pour les internautes.
II. Quelle est l’utilité d’ajouter un fichier robots.txt ?
Dans le but d’obtenir le meilleur référencement possible sur les différents moteurs de recherche, il est primordial de proposer des pages offrant le plus de valeur ajoutée possible aux utilisateurs. Il peut ainsi être utile de cacher des pages en cours de construction ou présentant des bugs.
Dans le cas d’un site comportant de très nombreuses pages, les robots qui « crawl » votre site disposent d’une limite de temps à allouer à votre site.
Il est donc efficace d’un point de vue SEO de donner la priorité à vos pages qui proposent le plus de valeur.
Pour rappel, le « crawl » est l’action menée par les robots pour déterminer le contenu d’une page web. Grâce à cette analyse, les moteurs de recherche vont pourvoir répondre plus précisément aux requêtes des utilisateurs.
III. Quel est le contenu à intégrer dans un fichier robots.txt ?
Un fichier robots.txt est divisé en 2 parties.
1. Les robots ciblés
En premier lieu, nous spécifierons « l’agent » ciblé. L’ « agent » ciblé est le robot avec lequel on souhaite communiquer. Pour exemple, si nous souhaitons cacher des pages aux robots de Google, l’agent serait :
User-agent : Googlebot
Dans une majorité des cas, il sera préférable d’informer la totalité des robots qui parcourent le web, comme ceux de Yahoo ou Bing par exemple. Pour cibler tous les agents possibles, il faut utiliser un astérisque (*).
Le format du robots.txt sera donc :
User-agent : *
2. Le contenu à autoriser ou à cacher
Une fois les robots ciblés, il faut spécifier les pages que vous souhaitez cacher.
Pour ce faire, trois possibilités s’offrent à vous :
a. Autoriser le crawl de certaines pages identifiées
La première méthode consiste à autoriser certaines pages seulement à être visitées par les robots Google. Le robot pourra donc « crawler » uniquement les pages spécifiées et n’en verra aucune autre. Pour ce faire, spécifiez le slug de la page à autoriser après avoir écrit « Allow »
Pour rappel, le slug d’une page est la partie de l’url qui lui correspond. Prenons l’exemple d’un site appelé « monsite.fr ».
L’url de la page de contact sera « https://www.monsite.fr/contact/ ». Le slug de la page contact est donc « /contact ».
Dans le cas de l’autorisation d’une page « Contact », le texte à écrire sera donc :
Allow : /contact
b. Interdire le crawl de certaines pages identifiées
La deuxième méthode consiste à interdire certaines pages seulement à être visitées par les robots Google. Nous vous recommandons cette méthode. Elle permet d’éviter des oublis pouvant conduire à cacher des pages que vous auriez voulu mettre en valeur.
On suivra ici une structure similaire, en écrivant le slug de la page après le mot-clé « Disallow ».
Pour reprendre le même exemple, cacher une page « contact » se fera en écrivant le texte :
Disallow : /contact
c. Combiner les deux méthodes sus-évoquées
En combinant les deux méthodes précédentes, on peut cibler des pages de manière précise. On peut par exemple interdire l’accès à un dossier, mais en autoriser une page spécifique.
Prenons l’exemple d’un article « top 10 astuces » au sein d’un blog. Si vous souhaitez interdire l’accès à l’ensemble du blog mais autoriser l’accès à cet article précis, vous pourrez écrire :
Disallow : /blog
Allow: /blog/top10astuces
Pour découvrir toutes les options disponibles, explorez la documentation Google sur le fichier robots.txt !
IV. Comment ajouter un fichier robots.txt sur Webflow ?
Pour ajouter un fichier robots.txt sur Webflow, rendez-vous dans les paramètres de votre site.
Vous trouverez dans l’onglet « SEO », dans l’encart « Indexing », la zone de texte pour modifier votre fichier robots.txt
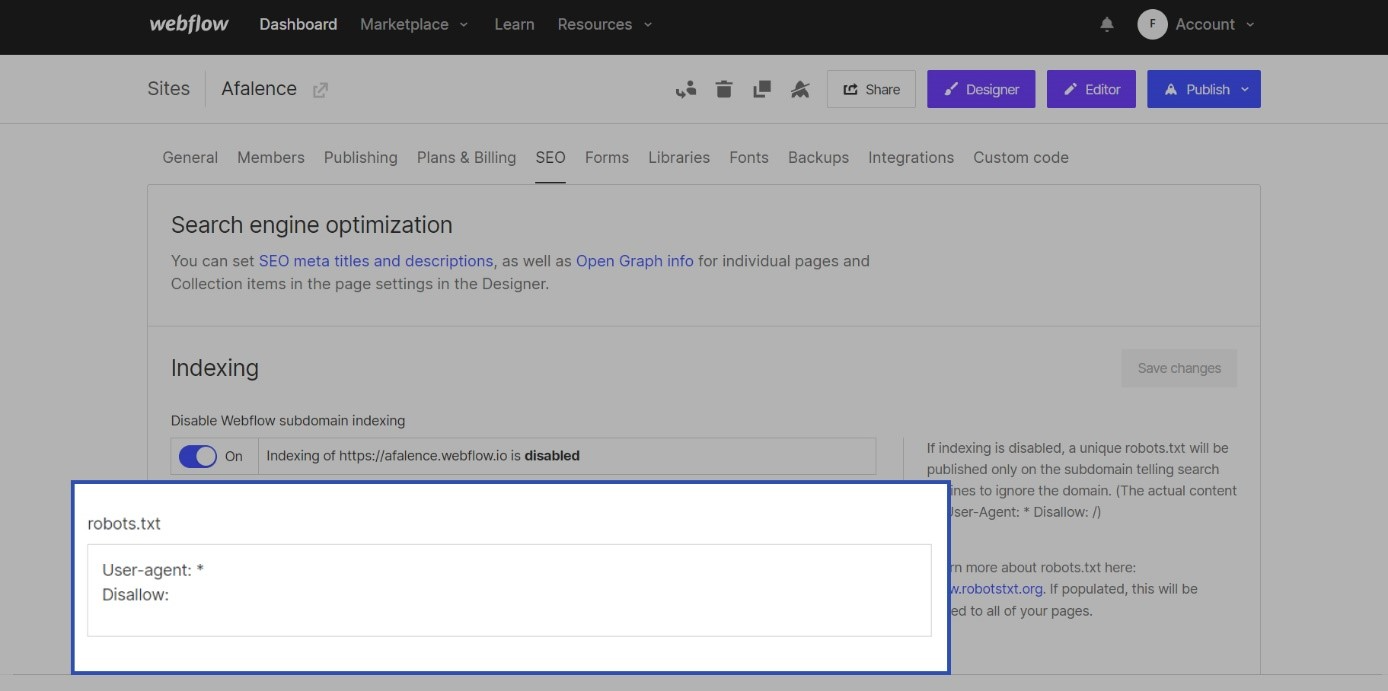
Une fois votre fichier rédigé, n’oubliez pas de cliquer sur « Save changes » pour sauvegarder vos changements. Cliquez ensuite sur « Publish » pour rendre votre fichier robots.txt effectif sur internet !
V. Nos Astuces
1. Autoriser le crawling de l’ensemble de vos pages
Dans le cas d’un site comportant moins de 10 000 pages, nous recommandons d’autoriser l’ensemble des pages pour tous les robots. Cette pratique permet d’éviter que des pages soient mal indexées, ce qui nuirait fortement à votre site d’un point de vue SEO.
Pour appliquer cette recommandation, vous pouvez copier le code suivant :
User-agent : *
Disallow :
2. Cacher ses statistiques aux concurrents
Au-delà des robots de Google et de Yahoo, de nombreux outils d’analyse créent également des robots qui « crawl » les sites web. Cette pratique a pour objectif d’obtenir des données équivalentes à celles de Google Analytics, qui sont normalement privées.
Ces données révèlent de nombreuses informations comme la densité du trafic, sa provenance, le taux de rebond… tant d’informations qui permettent d’identifier des stratégies SEO et d’obtenir un avantage sur ses concurrents.
Il est compliqué d’interdire l’accès à la totalité des robots d’analyse à cause de leur diversité. Par ailleurs, de nouveaux robots sont créés en permanence.
Nous vous partageons néanmoins une liste non exhaustive d’agents vous permettant de cacher vos données aux robots de crawl les plus fréquemment utilisés :
User-agent: AhrefsBot
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: Rogerbot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: ScoutJet
Disallow: /
User-agent: sistrix
Disallow: /
User-agent: SearchmetricsBot
Disallow: /
User-agent: SEOkicks-Robot
Disallow: /
User-agent: Lipperhey Spider
Disallow: /
User-agent: Exabot
Disallow: /
User-agent: NCBot
Disallow: /
User-agent: BacklinkCrawler
Disallow: /
User-agent: archive.org_bot
Disallow: /
User-agent: meanpathbot
Disallow: /
User-agent: PagesInventory
Disallow: /
User-agent: Aboundexbot
Disallow: /
User-agent: spbot
Disallow: /
User-agent: linkdexbot
Disallow: /
User-agent: Gigabot
Disallow: /
User-agent: dotbot
Disallow: /
User-agent: Nutch
Disallow: /
User-agent: BLEXBot
Disallow: /
User-agent: Ezooms
Disallow: /
User-agent: Majestic-12
Disallow: /
User-agent: Majestic-SEO
Disallow: /
User-agent: DSearch
Disallow: /
User-agent: MJ12
Disallow: /
User-agent: BlekkoBot
Disallow: /
User-agent: NerdyBot
Disallow: /
User-agent: JamesBOT
Disallow: /
User-agent: TinEye
Disallow: /
User-agent: Baiduspider
Disallow: /
User-agent: serpstat
Disallow: /
User-agent: spyfu
Disallow: /
Vous avez maintenant toutes les informations nécessaires pour utiliser au mieux les fichiers robots.txt !
Pour obtenir d’autres astuces autour du SEO sur Webflow, nous vous invitons à consulter notre guide complet sur le SEO sur Webflow !

Voir aussi nos autres articles
Discutons de vos besoins
Vous cherchez une agence web de confiance pour votre projet ? Contactez-nous et découvrez comment nous pouvons vous aider.